请注意,本文编写于 77 天前,最后修改于 71 天前,其中某些信息可能已经过时。
目录
一些名词
主要是整理了一些ai名词
1. LLM-大语言模型
基本都是基于函数transformer搭建
内部肯定有很多向量公式,这里简化不表
- 工作原理
- 单次对话:根据用户输入q与已经吐出的回答字段a1,不断预测新的输入字段a2...an,直到判断后输出结束标识符,本次回答a结束
- 类似while循环,退出条件是a结束
- a1...作为最底层的元,又叫做token
- 整个对话:根据已经产生的对话context,作为预先的输入,推测后续对话
- context作为上下文有限,窗口代表最大context额度(单位token)
- 单次对话:根据用户输入q与已经吐出的回答字段a1,不断预测新的输入字段a2...an,直到判断后输出结束标识符,本次回答a结束
2. token 单位元
作为大模型内部基本单位元,需要解码编码,token与实际的文字/单词具有一定映射关系。
token划分不一定符合文字直觉
1个token约为1.5汉字
- 解码过程
- 切割文字token,映射为数字token id,一个个输入给大模型
- 解码过程
- 映射数字为文字,模型每次只给一个token,拼接回上文
3. context 上下文
-
context window:最大容纳token数
-
包括了
-
之前所有对话记录
-
大模型正在追加的token
-
tool工具列表(大概是一些内置的工具api?sdk?)
-
system prompt
-
-
优化
- 优化在context的检索效率
- rag:从context抽取与用户问题最关联的片段,发给大模型
- 降低对话成本
- 优化在context的检索效率
4. prompt 提示词
- user prompt
- 单次对话输入的指令
- prompt engineering 提示词工程,模型变强之后可以不在乎
- system prompt
- 内置好的调教文案,用户不可访问
5. tool 内置工具
api & sdk内置给它让它调-面向大模型开发(?
-
涉及角色:用户,模型,工具,平台
- 平台:内嵌模型和工具的后台 + 面向用户的前台 + 调用各种能力 + 转发消息(json格式?)
- 网站 or app形式
- 平台:内嵌模型和工具的后台 + 面向用户的前台 + 调用各种能力 + 转发消息(json格式?)
-
工具接入平台的规范不一样
-
mcp协议
-
6. agent 智能体
-
agent:自主规划现状,自主调用工具的系统
-
agent 构建模式
-
ReAct
-
plan and execute
-
7. agent skill
预设好习惯要求,沉淀为skill md文档
- title + 指令层 + 示例

- cc使用skills示例
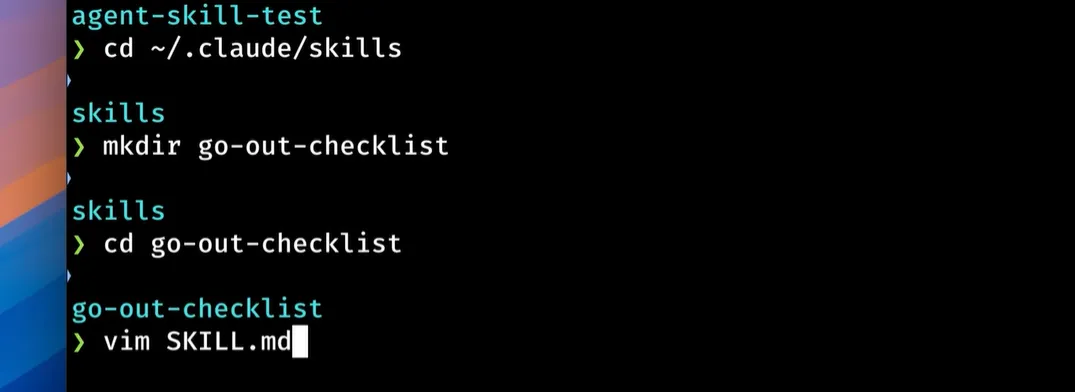
- 渐进式披露
目录